Monitoring Kubernetes workloads with AppDynamics and modern CD strategies
02 Jan 2023Monitoring Kubernetes workloads with AppDynamics and modern CD strategies
Many organizations move their applications onto cloud native infrastructure like Kubernetes or its’ “superstructures” like OpenShift or Rancher, both on premises and in the public clouds.
AppDynamics as a leading APM (Application Performance Monitoring) tool always offered support for workloads in those environments and aided monitoring needs from multiple angles. It offers platform monitoring, individual pod resource monitoring and deep application performance monitoring via specialized agents. While platform monitoring and pod monitoring is handled with one-time setup of a Cluster Agent, for APM, agents need to be embedded into application pods and there are multiple ways to do it – but there are a few specifically desired properties of the process in practice:
-
The process of embedding an agent should be easy from the developer standpoint, ideally transparent
-
The process should work well in context of CI/CD pipelines used
-
The method should be robust and work with all Kubernetes resource kinds like Deployments, StatefulSets, DaemonSets, Jobs, CronJobs, etc.
-
The method should not require elevated privileges for the process of embedding
AppDynamics Cluster Agent provides such feature called auto-instrumentation for Java, .NET, and Node.js applications out of the box, and while it works well, there are certain limitations, especially when using increasingly popular GitOps-based continuous deployment tools like Argo CD. Those tools compare application specification in the git repository with application running on a Kubernetes cluster, and when there are differences, git version wins and is automatically adjusted on the Kubernetes cluster.
Because AppDynamics Cluster Agent embeds the agents via dynamic changes of application resource definitions (like Deployments), tools like Argo CD detect that and revert the changes to the state defined in the git. Cluster Agent then sees the application ready for instrumentation again, does the injection again – and you get the idea by now – this process can go on forever. Also, Cluster Agent does not support some workload types like CronJobs.

Img. 1 – AppDynamics Cluster Agent auto-instrumentation process direct application deployment

Img. 2 – AppDynamics Cluster Agent auto-instrumentation process with Argo CD
Having multiple customers using AppDynamics and facing those or similar issues, I have been looking for a different way of the entire process. After some experimenting, I decided to approach the problem using a standard Kubernetes extension feature – mutating webhook. Mutating webhooks can be registered to certain resource events in the cluster, among many other events, to pod instantiation event. Then they can implement functionality, which modifies the resource - pod in our case - before it is created. This avoids the conflicts described above and works well with any kind of resource (except direct Pod deployment via Argo CD, for example, which is rare these days). As a result, I have developed a fully functional solution, published as an open-source project with Cisco Systems permission, and it is currently running in production at scale at multiple customers.

Img. 3 – Mutating Webhook-based auto-instrumentation process
If interested, feel free to use yourselves and here is how.
How To
The full project is hosted at github.com/cisco-open and alternatively available via Cisco DevNet Code Exchange
Clone the repo:
git clone https://github.com/cisco-open/appdynamics-k8s-webhook-instrumentor.git
Now we need to specify instrumentation rules. Since the instrumentation webhook is deployed using Helm, this is done by creating a file with values for Helm chart.
cd appdynamics-k8s-webhook-instrumentor/buildEnv/helm
cp values-sample.yaml my-values.yaml
In this example, we’re going to use AppDynamics native agents and native telemetry feed only, though we support AppDynamics agents hybrid mode with OpenTelemetry traces feed and also native OpenTelemetry agents - this I can cover in subsequent blogs.
Open my-values.yaml in your favourite text editor.
1. Find section appdController - fill in appropritate values
appdController:
host: <instance>.saas.appdynamics.com
port: "443"
isSecure: true
accountName: <instance>
accessKey: "xxxxxxxxxxx"
# following is optional - use only if using proxy to access SaaS controller
# useProxy: true
# proxyHost: proxy.corm.com
# proxyPort: "8080"
# following is optional - use only if using hybrid agent mode
# otelEndpoint: https://<region>-sls-agent-api.saas.appdynamics.com
# otelHeaderKey: "xxx"
2. Delete openTelemetryCollectors: section if not using OpenTelemetry and hybrid agent mode
3. Specify instrumentation templates for your languages in instrumentationTemplates section
instrumentationTemplates:
- name: Java_Default
injectionRules:
# technology = java | dotnetcore | nodejs
technology: java
image: appdynamics/java-agent:latest
javaEnvVar: JAVA_TOOL_OPTIONS
applicationNameSource: label
applicationNameLabel: appdApp
tierNameSource: auto
# optional otelNativeAgent: true -> assume native otel image use, no AppD native feed
# openTelemetryCollectors: deploymentHybridagentDefault
- name: Dotnet_Default
injectionRules:
technology: dotnetcore
image: appdynamics/dotnet-core-agent:22.5.1
applicationNameSource: label
applicationNameLabel: appdApp
tierNameSource: auto
- name: Nodejs_Default
injectionRules:
technology: nodejs
image: appdynamics/nodejs-agent:22.5.0-16-stretch-slim
applicationNameSource: label
applicationNameLabel: appdApp
tierNameSource: auto
AppDynamics agent needs a help with a few parameters - at least application name and tier name. applicationNameSource attribute tells where to get the application name from. Here we say - take it from Pod label and the label is appdApp as specified by applicationNameLabel attribute. tierNameSource attribute set to auto means that tier name will be derived from resources owning the Pod, which ends up being Deployment or StatefulSet name, for example.
Pls. note we always specify technology attribute which simply tells what framework the application uses and which agent type therefore to use. Agent is then delivered by specified image.
4. Specify selection rules for auto-instrumentaion
Since on Kubernetes cluster, there are usually many workloads running, where not all of them require agent deployment, there’s a need of a mechanism for selection of those workloads, where the agent deployment is needed. Also, we need to provide some hints what kind of technology (Java, .NET, …) the workload uses and we might have some special requirements related to naming conventions, logging, etc. All this is specified in the instrumentationRules: section like this:
instrumentationRules:
- name: java1
matchRules:
namespaceRegex: .*
labels:
- matchLabel: java1
- language: java
annotations:
- annot1: .*
podNameRegex: .*
injectionRules:
template: Java_Default
javaEnvVar: _JAVA_OPTIONS
Workloads can be selected by multiple criteria and typically, there’s more than one instrumentation rule in a real setup. Rules are evaluated sequentially till the first match. Match rules can be specified by matchRules attribute on multiple workload attributes:
- namespaceRegex - only workloads in namespaces matching the regexp are instrumented
- labels - only pods having the labels with the values matching the regexp specified in the instrumentation rule are instrumented. When multiple labels are used, all of them must match
- annotations - similar to labels, but using annotations
- podNameRegex - only pods with name matching the regexp are instrumented
When multiple criteria are used, all of them must match (logical AND is used - if OR is needed, create another instrumentation rule)
Injection rules in the injectionRules attribute typically refer to instrumentationTemplate and can override values in the templates.
In the example above, Deployment like this would match the rules:
- can be in any namespace
- can create pod of any name
- must have two labels on (pod) template/spec level:
matchLabelwith value containingjava1andlanguagewith value containingjava - must have annotation on (pod) template/spec level:
annot1with any value
5. Deploy the mutating webhook instrumentor using helm
Create namespace for the webhook if it does not exist:
kubectl create namespace mwh
Deploy webhook using helm:
helm install --namespace=mwh mwh . --values=my-values.yaml
Verify, that webhook is running:
kubectl -n mwh get pods

6. Deploy sample application
Now it’s time to test the instrumentation. Use your application if you have some, or simply use mine testing Java application using published image like following.
Create resource definition file d-downstream.yaml and paste following content into it:
apiVersion: apps/v1
kind: Deployment
metadata:
name: downstream
spec:
replicas: 1
selector:
matchLabels:
app: downstream
template:
metadata:
annotations:
annot1: my-annotation
labels:
app: downstream
appdApp: My-instr-java-app
matchLabel: java1
language: java
spec:
containers:
- name: downstream
image: chrlic/java-test-downstream:v1.0
imagePullPolicy: Always
ports:
- containerPort: 8181
resources:
limits:
cpu: "1"
memory: 500Mi
requests:
cpu: 250m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: downstream
labels:
run: downstream
spec:
ports:
- port: 8282
targetPort: 8181
protocol: TCP
selector:
app: downstream
type: LoadBalancer
save and deploy:
kubectl create namespace test
kubectl -n test apply -f d-downstream.yaml
Check if the application pod is running:
kubectl -n test get pods
See, if instrumentation worked by looking at the pod in detail
kubectl -n test get pod <pod-name> -o yaml
At the end, you should see finished initContainer with Java agent image
Now, you can run test calls from browser or using curl:
curl http://localhost:8282/downstream/hello
You should see Greetings from DownStream!!! as a response, if empty response is returned, wait a few seconds and retry.
Application My-instr-java-app now should exist in AppDynamics and after a while (1-2 minutes), you should see application flowmap and stats.
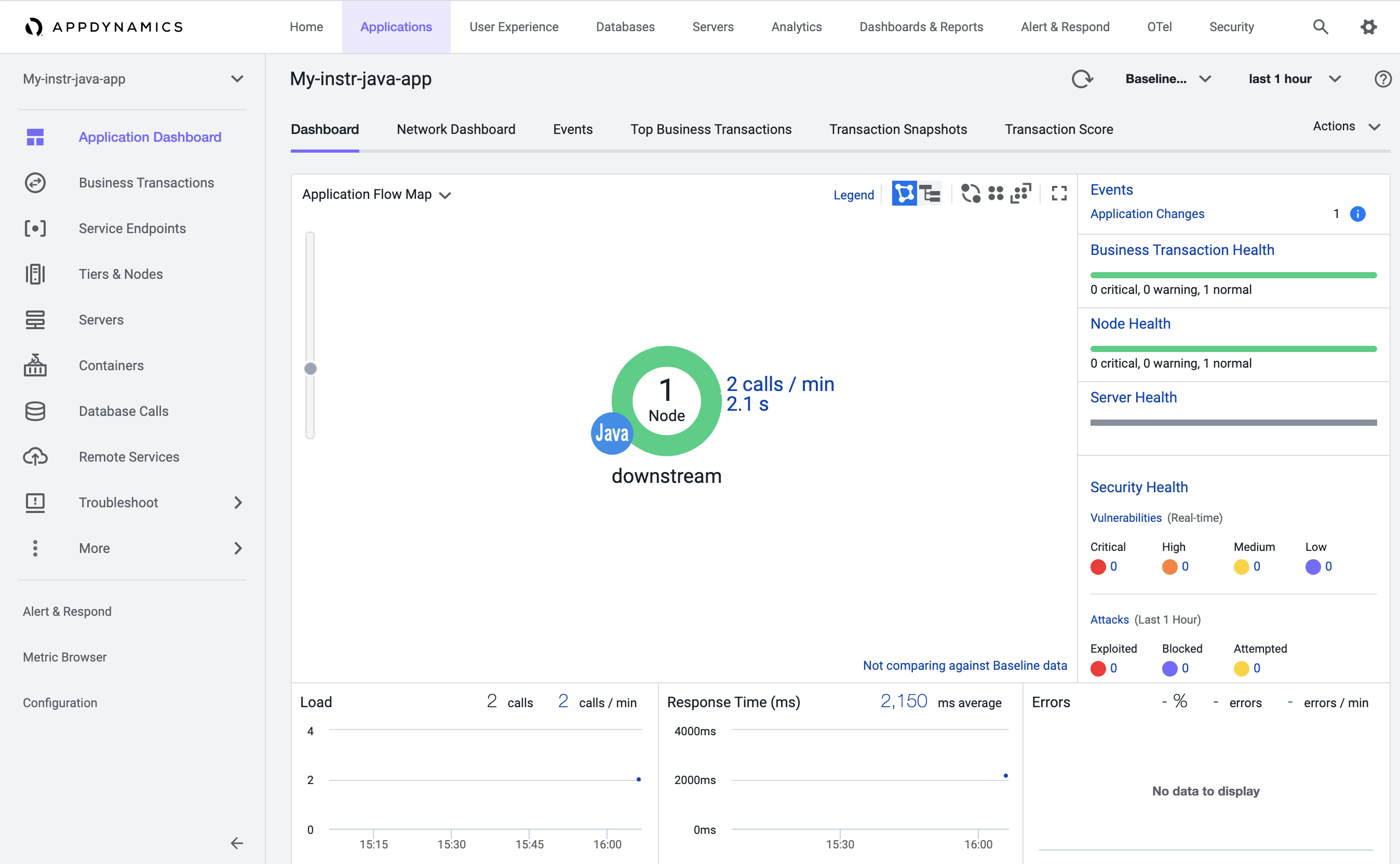
Congratulation, if you made it here!
Closing words
It could look like the method provided via mutating webhook brings only benefits. In reality, standard Cluster Agent does a bit more than instrumentation itself. It is, for example, capable of de-instrumentation in case workload starts failing after agent deployment. While this is extremely rare case, it can happen. Mutating webhook instrumentor has no such capability.
Cluster Agent is also needed for Kubernetes cluster monitoring itself and in the environments using Infrastructure Based Licensing, it keeps track of workloads to infrastructure relationships and therefore enables proper bookkeeping of license consumption in the container platform environments. So, should you decide to use Mutating webhook instrumentor, deploy also Cluster Agent and just do not use it’s auto-instrumenation features.